Pengukuran
penyimpangan adalah suatu ukuran yang menunjukkan tinggi rendahnya perbedaan
data yang diperoleh dari rata-ratanya. Macam-macam pengukuran penyimpangan yang
sering digunakan adalah rentangan (range), rentangan antar kuartil,
rentangan semi antar kuartil, simpangan rata-rata, simpangan baku, varians,
koefisien varians, dan angka baku.
Rentangan
(range)
Range
(rentangan) adalah jarak antara nilai data yang tertinggi dengannilai data yang
terendah atau nilai tertinggi dikurangi nilai terendah.;
Rumus : data
tertinggi – data terendah
Contoh :
data nilai UAS Statistika
Kelas A : 90
80 70 90 70 100 80 50 75 70
Kelas B : 80
80 75 95 75 70 95 60 85 60
Langkah-langkah
menjawab :
Urutkan dulu
kemudian dihitung rentangannya.
Kelas A : 50
70 70 70 75 80 80 90 90 100
Kelas B : 60
60 70 75 75 80 80 85 95
Rentangan
kelas A : 100 – 50 = 50
Rentangan
kelas B : 95 – 60 = 35
2. Simpangan
Rata-rata (mean deviation)
Simpangan
rata-rata merupakan penyimpangan nilai-nilai individu dari nilai rata-ratanya.
Rata-rata bisa berupa mean atau median. Untuk data mentah simpangan rata-rata
dari median cukup kecil sehingga simpangan ini dianggap paling sesuai untuk
data mentah. Namun pada umumnya, simpangan rata-rata yang dihitung dari mean
yang sering digunakan untuk nilai simpangan rata-rata.
Data tunggal
dengan seluruh skornya berfrekuensi satu
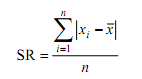
dimana xi merupakan
nilai data
Data tunggal
sebagian atau seluluh skornya berfrekuensi lebih dari satu
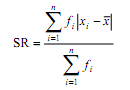
dimana xi merupakan
nilai data
VARIANS
Varians dan standar deviasi adalah sebuah
ukuran penyebaran yang menunjukan standar penyimpangan atau deviasi data
terhadap nilai rata-ratanya.
Varians adalah rata-rata hitung deviasi
kuadrat setiap data terhadap rata-rata hitungnya. Varians dapat dibedakan
antara varians populasi dan varians sampel. Varians populasi (σ dibaca tho)
adalah deviasi kuadrat dari setiap data terhadap rata-rata hitung semua data
dalam populasi. Varians sampel adalah deviasi kuadrat dari setiap data
rata-rata hitung terhadap semua data dalam sampel dimana sampel adalah bagian
dari populasi.

Varians memiliki kelemahan dimana nilai varians dalam bentuk kuadrad, seperti
tahun kuadrat dalam hal tertentu lebih suit menginterpretasikannya dibandingkan
dengan ukuran range yang merupakan selisih nilai tertinggi dan nilai terendah
atau deviasi rata-rata yang merupakan rata-rata hitung selisih data dari
rata-rata hitungnya. Oleh sebab itu, untuk memperoleh satuian yang sama dengan
satuan data awal, maka dilakukan dengan mencari akar kuadrad dari varians
populasi. Akar kuadrad dari varians populasi disebut standar deviasi.
Standar Deviasi
Standar deviasi disebut juga simpangan
baku. Seperti halnya varians, standar deviasi juga merupakan suatu ukuran
dispersi atau variasi. Standar deviasi merupakan ukuran dispersi yang
paling banyak dipakai. Hal ini mungkin karena standar deviasi mempunyai
satuan ukuran yang sama dengan satuan ukuran data asalnya. Misalnya, bila
satuan data asalnya adalah cm, maka satuan standar deviasinya juga cm.
Sebaliknya, varians memiliki satuan kuadrat dari data asalnya (misalnya cm2).
Simbol standar deviasi untuk populasi adalah σ (baca: sigma) dan untuk sampel
adalah s.
Standar Deviasi Untuk
Populasi

Standar Deviasi Untuk
Sampel
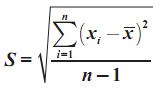
Contoh data tunggal
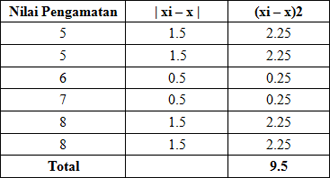
Untuk mendapatkan nilai variansi dan standar
deviasi dari contoh di atas dapat kita lihat pada penjelasan berikut ini:
- Dari contoh tersebut diatas sudah
jelas dari mana kita mendapatkan (xi – x)2 tersebut.
- Variansi yang akan kita pakai
disini juga variansi sampel, karena data yang kita gunakan adalalah data
sampel. Dari rumus diatas sudah jelas bagai mana kita dapat mendapatkan
nilai tersebut.
- Jadi, Variansi: Sampel (s2) =
9.5 / 5 = 1.9. Varian sampel yang kita dapat yaitu: 1.9. dan Standar
Deviasi (S) = √1.9 = 1.38.
Varians dan Standar Deviasi data Kelompok
Rumus varians dan standar deviasi untuk data
kelompok adalah sebagai berikut

Contoh dari Varians dan Standar Deviasi untuk
data berkelompok
Berikut merupakan nilai statistik dari 50
mahasiswa.
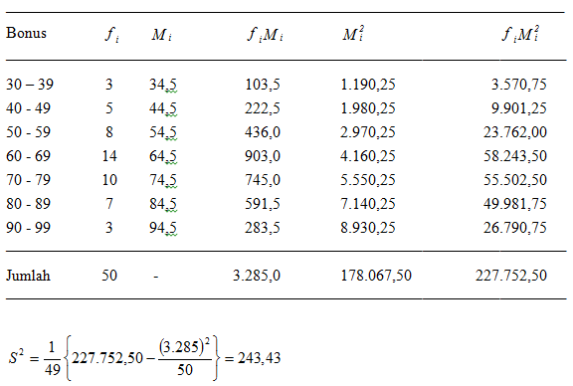
Kegunaan deviasi rata-rata dan deviasi standar
Baik deviasi rata-rata maupun deviasi standar
keduanya berguna sebagai ukuran untuk mengetahui variabilitas data dan untuk
mengetahui homogenitas data.
Daftar Pustaka:
- http://ar-ridhwank.blogspot.com/2012/10/statistika-pengukuran-penyimpangan.html
- http://digensia.wordpress.com/2012/03/15/statistik-deskriptif/
- http://www.smartstat.info/statistika/statisika-deskriptif/ukuran-penyebaran-measures-of-dispersion.html





















